[프로그래머스] 힙(Heap) - 더맵게 (python)
- 프로그래밍/프로그래머스
- 2020. 5. 10. 03:09
힙(Heap) 자료구조에 대해
자료구조에서 힙(Heap)은 최대힙과 최소힙이 있는데 최대힙의 경우 모든 부모 노드의 값이 자식 노드의 값보다 크거나 같은 값을 갖는 이진 트리를 말한다. 이런 힙을 배열을 통해 표현하게 되는데 힙 배열에서의 부모 노드와 자식 노드의 관계는 부모의 인덱스를 x라고 했을 때, 왼쪽 자식의 인덱스는 x*2, 오른쪽 자식의 인덱스는 (x*2)+1이 된다.

그리고 이러한 힙의 특징을 사용하면 우선순위 큐를 구현할 수 있게 되는데, 스택이 제일 마지막에 들어온 값을 먼저 꺼내는 자료구조고 큐가 제일 먼저 들어온 값을 꺼내는 자료구조라면 우선순위 큐는 가장 우선순위가 높은 값이 먼저 꺼내지는 자료구조이다. 즉, 최댓값 및 최솟값을 찾아내는 연산을 빠르게 하기 위해 고안된 자료구조라고 보면 된다.
파이썬에서는 우선순위 큐 알고리즘의 구현을 제공하는 heapq 모듈을 제공한다. heappush를 사용하면 힙에 값을 push할 수 있고 heappop을 사용하면 힙에서 값을 꺼낼 수 있다. 특히 heapify를 사용하면 리스트 x를 힙으로 변환시킬 수 있다.
heapq 주요 함수 (출처: python.flowdas.com)
heapq.heappush(heap, item)
힙 불변성을 유지하면서, item 값을 heap으로 푸시합니다.
heapq.heappop(heap)
힙 불변성을 유지하면서, heap에서 가장 작은 항목을 팝하고 반환합니다. 힙이 비어 있으면, IndexError가 발생합니다. 팝 하지 않고 가장 작은 항목에 액세스하려면, heap[0]을 사용하십시오.
heapq.heappushpop(heap, item)
힙에 item을 푸시한 다음, heap에서 가장 작은 항목을 팝하고 반환합니다. 결합한 액션은 heappush()한 다음 heappop()을 별도로 호출하는 것보다 더 효율적으로 실행합니다.
heapq.heapify(x)
리스트 x를 선형 시간으로 제자리에서 힙으로 변환합니다.
힙(Heap) - 더맵게, 문제확인
문제설명은 아래와 같다.
모든 음식의 스코빌 지수를 K 이상으로 만드는 것이 목적
스코빌 지수가 가장 낮은 두개의 음식을 섞어 새로운 음식을 만들게 됨
섞은 음식의 스코빌 지수 = 가장 맵지 않은 음식의 스코빌 지수 + (두 번째로 맵지 않은 음식의 스코빌 지수 * 2)
음식의 스코빌 지수를 담은 배열 scoville와 K 값이 주어짐
모든 음식의 스코빌 지수가 K 이상이 되게 하기 위해 섞어야 하는 최소 횟수를 리턴
단, 모든 음식의 스코빌 지수를 K 이상으로 만들 수 없는 경우에는 -1을 리턴
힙(Heap) - 더맵게, 문제풀이
문제가 간단하기 때문에 따로 예제를 살펴보진 않아도 될 것 같다. 위에서 살펴본 heapq 모듈을 사용해서 먼저 스코빌 지수가 담긴 배열 scoville를 힙 배열로 변경해준다.
import heapq
def solution(scoville, K):
count=0
heapq.heapify(scoville)
그리고 가장 작은 스코빌 지수 2개인 scoville[0]과 scoville[1]을 섞어 새로운 스코빌 지수인 new_num을 만든다. 새로운 스코빌 지수를 만들었으므로 scoville 배열에서 인덱스 0, 1은 pop해주고 new_num을 push해준다.
while 1:
# 코드...
new_num=scoville[0]+(scoville[1]*2)
heapq.heappop(scoville)
heapq.heappop(scoville)
heapq.heappush(scoville,new_num)
count+=1
그리고 해당 코드 위에 조건문들을 추가해준다. 첫번째 조건문은 문제 설명에 있었던 "단, 모든 음식의 스코빌 지수를 K 이상으로 만들 수 없는 경우에는 -1을 리턴"에 대한 처리를 해주기 위한 조건문이다. scoville 배열에 값이 1개 이하가 남았고 그 하나의 값이 K 미만이라면 count를 0으로 해주고 반복문을 끝내버린다.
while 1:
if len(scoville)<=1 and scoville[0]<K:
count=0
break
if scoville[0]>=K:
break
마지막으로 count 값이 0이라면 모든 값을 K 이상으로 만들 수 없는 것이므로 -1을 리턴하고 그 외는 count 값을 리턴해준다.
if count==0: return -1
else: return count
그런데 이렇게만 하면 테스트 케이스 일부에서 실패가 뜬다. 질문하기에도 별다른 테스트케이스를 발견하지 못하고 다시 문제설명을 읽다보니 count 값이 0이 되면 무조건 리턴값이 -1이 된다는 사실을 알았다. scoville 배열이 [3,3,3]이고 K가 3이면 count=0으로 끝나고 리턴값이 0이 되야 하는데 아래 코드대로라면 -1이 리턴된다.
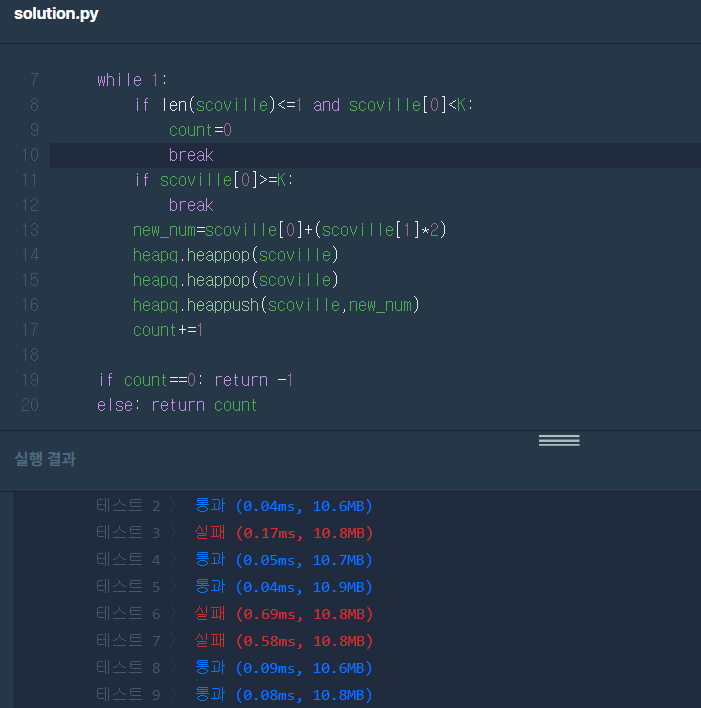
따라서 코드를 아래와 같이 변경해주었다. 하지만 내 예상과는 다르게 똑같이 3,6,7 테스트케이스에서 실패가 떴다.
import heapq
def solution(scoville, K):
count=0
heapq.heapify(scoville)
while 1:
if len(scoville)<=1 and scoville[0]<K:
count=-1
break
if scoville[0]>=K:
break
new_num=scoville[0]+(scoville[1]*2)
heapq.heappop(scoville)
heapq.heappop(scoville)
heapq.heappush(scoville,new_num)
count+=1
return count
다시 하나의 배열을 정하고 K 값을 변경하면서 5개의 테스트케이스를 추가해보았다.
-
[1,1,2,6] 1 0
-
[1,1,2,6] 2 1
-
[1,1,2,6] 6 2
-
[1,1,2,6] 8 3
-
[1,1,2,6] 30 -1
여기서 배열이 [1,1,2,6]이고 K가 30일 때, 리턴값이 -1이 되야 되는데 3이 나온걸 확인했다.
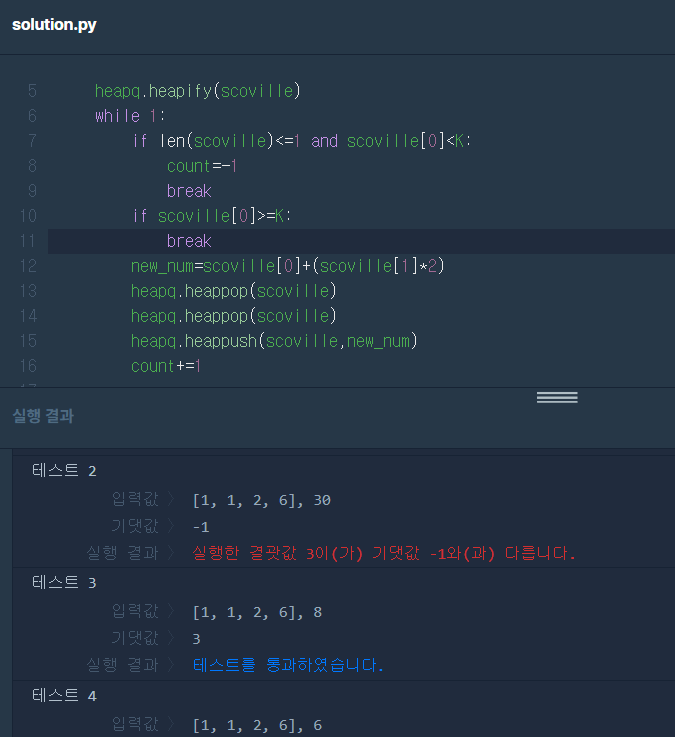
뭐가 문제인지 보기 위해 print로 scoville과 count를 찍어봤는데 heappop과 heappush를 할 때 배열이 자동으로 최소-> 최대값 순으로 정렬되는 것이 아니었다. 제일 스코빌 지수가 낮은 값이 scoville[0]으로 생각한게 잘못이었다.

따라서 아래와 같이 코드를 다시 변경했다.
import heapq
def solution(scoville, K):
count=0
heapq.heapify(scoville)
while 1:
if len(scoville)<=1 and scoville[0]<K:
count=-1
break
if scoville[0]>=K:
break
new_num= heapq.heappop(scoville)+(heapq.heappop(scoville)*2)
heapq.heappush(scoville,new_num)
count+=1
return count
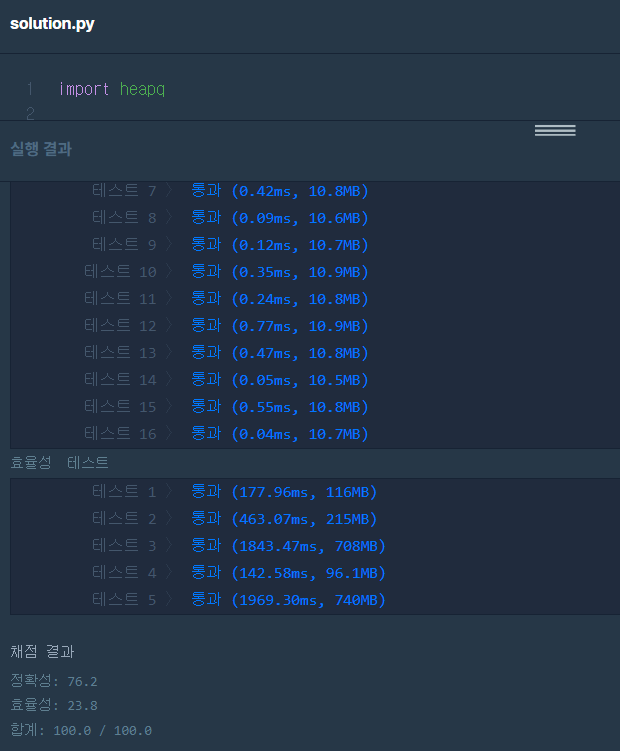
이제야 모든 테스트 케이스를 통과하게 되었다.
참고자료
https://gmlwjd9405.github.io/2018/05/10/data-structure-heap.html
https://python.flowdas.com/library/heapq.html
'프로그래밍 > 프로그래머스' 카테고리의 다른 글
| [프로그래머스] 정렬 - K번째수 (python) (0) | 2020.05.17 |
|---|---|
| [프로그래머스] 힙(Heap) - 라면공장 (python) (0) | 2020.05.11 |
| [프로그래머스] 스택/큐 - 주식가격 (python) (0) | 2020.05.06 |
| [프로그래머스] 스택/큐 - 쇠막대기 (python) (0) | 2020.05.04 |
| [프로그래머스] 스택/큐 - 프린터 (python) (0) | 2020.05.03 |