파이썬 KoNLPy를 사용한 한글 명사 추출 및 빈도 계산
- 프로그래밍/파이썬
- 2020. 2. 14. 20:19
KoNLPy 란
아무래도 언어마다 자연어처리를 하기 위한 특성이 제각각이다보니 영어에 맞춰진 자연어처리 도구를 사용하기는 한글에는 맞지 않는다. 그런 이유에서 한글 자연어 처리에 맞춤화된 파이썬 오픈소스 라이브러리인 KoNLPy가 등장했다. 일명 '파이썬 한글 평태소 분석기'이다. 처음엔 당연히 '코엔엘피와이'라고 생각했는데 읽는 방법은 '코엔엘파이'라고 한다.
KoNLPy 설치는 pip로 바로 설치되지는 않는다. 그전에 자바 jdk와 Jpype가 설치되어있어야 하는데 자세한 설치 방법은 아래 포스팅을 참고해주기 바란다.
관련포스팅
KoNLPy (파이썬 한글 형태소 분석기 ) 윈도우 설치 방법
KoNLPy (파이썬 한글 형태소 분석기 ) 윈도우 설치 방법
파이썬 한글 형태소 분석기인 KoNLPy 설치는 아래 기입된 순서대로, 본인 환경(파이썬 버전, 윈도우 비트)에만 맞게 진행해주면 에러가 발생하지 않는다. 참고로 나의 환경은 '파이썬3.8, 윈도우10 x64'이다. 자바..
liveyourit.tistory.com
KoNLPy 형태소 분석기 클래스
KoNLPy에는 형태소 분석기가 클래스로 포함되어 있는데 아래와 같이 총 5개이다. 본인이 원하는 분석기를 선택해 임포트시킨 후 객체를 생성해서 사용해주면 된다. 해당 포스팅에서는 Okt (Twitter) 클래스를 사용해 한글 명사 단어 빈도를 계산해줄 것이다.
- Hannanum
- Kkma
- Komoran
- Mecab
- Okt(Twitter)
KoNLPy Okt 클래스 사용법
Okt 객체는 아래와 같이 선언해준다. 명사 빈도를 계산해보기 전에 제공되는 함수들의 간단한 사용법을 알아보자.
from konlpy.tag import Okt
# Okt 객체 선언
okt = Okt()
morphs(phrase)
morphs는 형태소 단위로 구문 분석을 수행한다.

nouns(phrase)
nouns는 명사만 추출해준다. 띄어쓰기를 안하거나 명사를 마구잡이로 연결해서 써도 추출이 잘된다.

phrases(phrase)
phrases는 어절만 추출해준다.

pos(phrase, norm=False, stem=False)
pos는 형태소 단위로 쪼갠 후 각 품사들을 태깅해서 리스트 형태로 반환해준다. 아래 예문으로 사용한 문장을 보면 알겠지만 영어단어는 'Alpha'로 '^^'와 같은 기호?는 Puntuation, 'ㅋㅋㅋ'는 KoreanParticle 로 분석해준다. 이런 편리한 모듈을 왜 이제알았는지 싶다.

추가적인 클래스나 사용법은 아래 공식 페이지를 참조하면 좋을 것 같다.
https://konlpy-ko.readthedocs.io/ko/v0.4.3/
KoNLPy: 파이썬 한국어 NLP — KoNLPy 0.4.3 documentation
KoNLPy: 파이썬 한국어 NLP KoNLPy(“코엔엘파이”라고 읽습니다)는 한국어 정보처리를 위한 파이썬 패키지입니다. 설치법은 이 곳을 참고해주세요. NLP를 처음 시작하시는 분들은 시작하기 에서 가볍게 기본 지식을 습득할 수 있으며, KoNLPy의 사용법 가이드는 사용하기, 각 모듈의 상세사항은 API 문서에서 보실 수 있습니다. >>> from konlpy.tag import Kkma >>> from konlpy.utils import pprin
konlpy-ko.readthedocs.io
KoNLPy를 사용한 한글 명사 빈도 계산
그럼 이제, 본 포스팅의 목적이었던 한글 명사 빈도를 KoNLPy를 사용해 계산해보자. 위 사용법에서 보았다시피 Okt 클래스의 nouns 함수를 사용하면 된다. 사실, 위 페이지를 확인하면 Twitter 클래스밖에 나오지 않는데 Twitter 클래스를 사용했더니 KoNLPy 몇 버전 이상에서는 Okt를 사용하는게 좋다는 경고 메시지가 나와서 Okt를 사용했으니 참고하길 바란다.
nouns라는 편리한 함수가 있으니 명사 빈도 계산은 코드 몇줄이면 끝난다. 위에서 임포트시켰던 Okt와 함께 collections 모듈의 Counter를 임포트시킨다.
from konlpy.tag import Okt
from collections import Counter
okt 객체를 생성한 후 nouns 함수를 사용해 추출한 명사를 카운트하기 위해 Counter에 넘겨준다. 참고로 명사를 추출하기 위한 텍스트는 준비되어있다고 가정했는데 나는 보안뉴스 기사를 크롤링한 txt 파일을 읽어서 넘겨주었다. most_common은 빈도가 높은 n개의 명사를 추출해주기 때문에 본인이 원하는 수를 인자로 주면 된다.
f = open(filename,'r',encoding='utf-8')
news = f.read()
# okt 객체 생성
okt = Okt()
noun = okt.nouns(news)
count = Counter(noun)
# 명사 빈도 카운트
noun_list = count.most_common(100)
for v in noun_list:
print(v)
그럼 아래와 같이 추출됐던 명사와 그 명사가 얼마나 등장했는지 카운트된 수를 함께 확인할 수 있다. 그런데 결과를 확인해보니 명사가 맞긴 하지만 키워드라고 하기는 힘든 '것', '수', '등', '위' 와 같은 한글자 명사들이 상위에 등장한다.
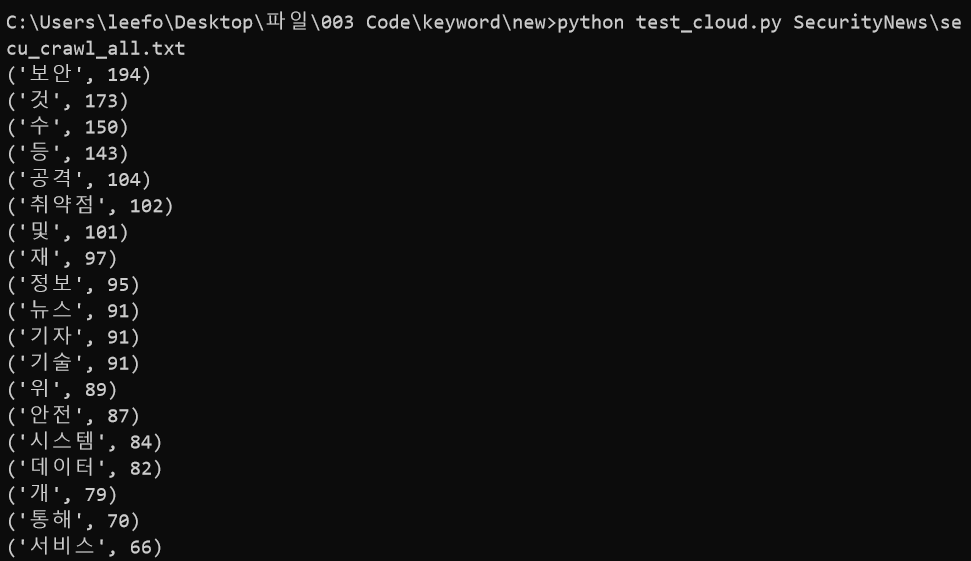
나는 한글자인 명사는 빼주기로 했다.
f = open(filename,'r',encoding='utf-8')
news = f.read()
# okt 객체 생성
okt = Okt()
noun = okt.nouns(news)
for i,v in enumerate(noun):
if len(v)<2:
noun.pop(i)
count = Counter(noun)
# 명사 빈도 카운트
noun_list = count.most_common(100)
for v in noun_list:
print(v)
명사와 명사 출현 빈도가 들어있는 튜플 리스트를 얻었으니 최대 빈도의 명사 몇개만 추출한다던지 딕셔너리형태로 저장한더던지 등의 추후 응용은 쉽게 할 수 있을 것이다.

KoNLPy를 사용한 한글 명사 빈도 계산, 전체코드
전체 코드는 아래와 같다. 추가적으로 txt 파일이나 csv 파일에 저장할 수 있게 했다.
from konlpy.tag import Okt
from collections import Counter
import csv
filename = "SecurityNews\\secu_crawl_all.txt"
f = open(filename,'r',encoding='utf-8')
news = f.read()
# okt 객체 생성
okt = Okt()
noun = okt.nouns(news)
for i,v in enumerate(noun):
if len(v)<2:
noun.pop(i)
count = Counter(noun)
f.close()
# 명사 빈도 카운트
noun_list = count.most_common(100)
for v in noun_list:
print(v)
# txt 파일에 저장
with open("noun_list.txt",'w',encoding='utf-8') as f:
for v in noun_list:
f.write(" ".join(map(str,v))) #튜플 int값을 str 타입으로 전환 후 조인
f.write("\n")
# csv 파일에 저장
with open("noun_list.csv","w", newline='',encoding='euc-kr') as f:
csvw = csv.writer(f)
for v in noun_list:
csvw.writerow(v)
이렇게 얻은 한글 명사 빈도를 파이썬 wordcloud를 사용해 시각화를 해보는 방법은 아래 링크되어있는 다음 포스팅을 참고해주기 바란다.
관련포스팅
파이썬 wordcloud를 사용한 한글 명사 시각화
파이썬 wordcloud는 중요한 단어나 키워드를 시각화해서 보여주는 시각화 도구이다. wordcloud 자체적으로 빈도수를 계산하는 기능이 있다고 하지만 아무래도 한글의 특성이 있다보니, 나는 한글 명사를 추출하고..
liveyourit.tistory.com
[파이썬] 보안 뉴스 기사 크롤링하기 (제목, 본문 원하는만큼)
[파이썬] 보안 뉴스 기사 크롤링하기 (제목, 본문 원하는만큼)
뉴스 기사 크롤링 첫번째 - 보안뉴스 뉴스 기사 크롤링, 뉴스 기사 크롤러 만들기 첫번째 대상은 '보안뉴스' 이다. 왜냐면 내가 보안 종사자이기 때문이다. 어쨌든 보안뉴스 #전체기사 부분에서 기사 제목과 본문,..
liveyourit.tistory.com
'프로그래밍 > 파이썬' 카테고리의 다른 글
| [파이썬] 네이버 플레이스, 맛집 (JSON 데이터) 크롤링 (1) (8) | 2020.06.12 |
|---|---|
| 파이썬 wordcloud를 사용한 한글 명사 시각화 (8) | 2020.02.15 |
| KoNLPy (파이썬 한글 형태소 분석기 ) 윈도우 설치 방법 (9) | 2020.02.14 |
| [파이썬] 보안 뉴스 기사 크롤링하기 (제목, 본문 원하는만큼) (0) | 2020.02.07 |
| [파이썬] Selenium alert 경고창 처리하기 (8) | 2020.02.07 |