[파이썬] 동적 웹 크롤링 (2) - Selenium 을 활용해야 하는 이유? 자바스크립트 실행
- 프로그래밍/파이썬
- 2020. 1. 24. 17:22
Selenium webdriver를 사용해서 웹크롤링을 수행할 경우 일반 크롤링과 어떻게 다르고, 어떤 경우에 활용되어야 좋은지 확인해본다. 다음 포스팅들에서는 Selenium으로 각 Element에 접근하는 방법 등 실제 사용방법을 알아보고 해당 내용과 연계하여 코인마켓캡의 시가총액 등 관련 데이터들을 직접 크롤링하는 코드를 작성해보려 한다.
이전포스팅
[파이썬] 동적 웹 크롤링 (1) - Selenium webdriver 설치 및 사용
[파이썬] 동적 웹 크롤링 (1) - Selenium webdriver 설치 및 사용
파이썬 Selenium(셀레니움) webdriver를 사용해서 웹크롤링을 수행하기 위해 Selenium 모듈 설치, 사용할 브라우저, 브라우저의 드라이버를 설치해보고 사용방법을 간단히 알아본다. 추가적으로 chromedriver 경로..
liveyourit.tistory.com
웹 크롤링 시 Selemium을 활용하면 좋은 이유
간혹 인터넷에서 아래와 같은 질문을 보곤 한다. 나역시 '동적 웹 크롤링'이라는 것을 알기 전에 이와같이 생각했고, 공부하면서 알게되었다.
"beautifulSoup으로 소스를 가져왔는데 원하는 데이터가 없어요"
beautifulSoup으로 가져오느 소스에 원하는 데이터가 없는 이유는 해당 소스는 자바스크립트로 데이터가 내려지기 전의 html 소스이기 때문이다. 이런 경우, Selenium 모듈을 사용해 크롤링을 수행해야 한다.
Selenium은 webdriver라는 API를 통해 운영체제에 설치된 크롬 등의 브라우저를 제어하게 된다. 브라우저를 직접 동작시킨다는 것은 자바스크립트를 이용해 비동기적으로 혹은 뒤늦게 불러와지는 컨텐츠들을 가져올 수 있다는 뜻이다.
즉, 단순 requests의 경우 브라우저에서 ‘소스보기’를 한 것과 같이 동작하여, 자바스크립트가 실행되기 전인, DOM이 변하기 전의 HTML을 보게되는 반면, Selenium 모듈을 사용하면 실제 웹 브라우저를 동작시킬 수 있기 때문에 자바스크립트로 렌더링이 완료된 후의 DOM결과물에 접근이 가능하다.
Selenium 사용해서 비트코인 금액 가져오기
아래 비트코인 고팍스 거래소를 예로 들어보자. 아무래도 직접 webdriver가 브라우저 제어권을 가져온 후, 브라우저를 제어하면서 해당 URL에 직접 접근해 데이터를 내려받고 나서 코드대로 움직이다 보니 상당히 느리다는 단점이 있다. 그래서 그나마 빨리 랜더링되는 비트코인 페이지를 찾았는데, 고팍스가 그나마 빠른 것 같다.
분명히 페이지에 '9,720,000'이라는 금액이 존재한다. 당연히 이 금액은 계속 변동된다.
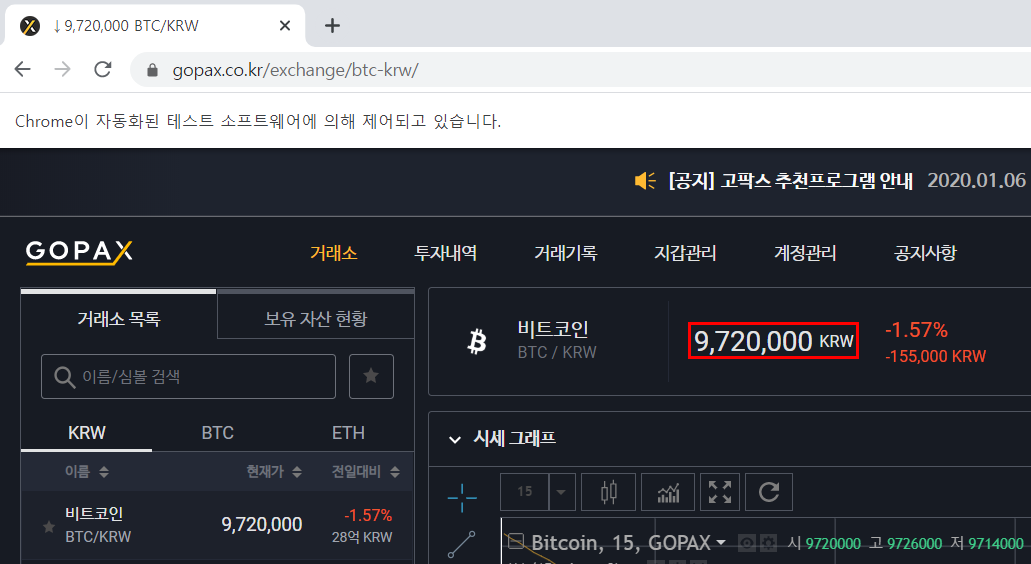
그런데 아무리 '소스보기'를 통해 아무리 html을 보아도 해당 금액은 찾을 수 없다. 자바스크립트를 기반으로, 동적으로 클라이언트에게 내려지기 때문이다. 만약에 해당 금액과 관련한 데이터들을 크롤링하고 싶다면, 단순 크롤링으로는 데이터에 접근할 수 없는 것이다. 애초에 html 소스가 엄청 짧다. 비트코인과 같이 시시각각으로 금액이 변동되는 경우 당연히 자바스크립트가 많이 사용되었을 것이다.

하지만 selenium을 사용하면, 내가 원하는 비트코인 금액관련 데이터를 얻을 수 있다. 크롬 개발자 도구를 실행시켜 원하는 데이터를 select한 뒤, 어떤 위치에 값이 들어가있는지 확인한다. 아래 사진을 보면, 내가 선택한 값은 div class name, PriceIndicator__price로 접근하면 될 것 같다.
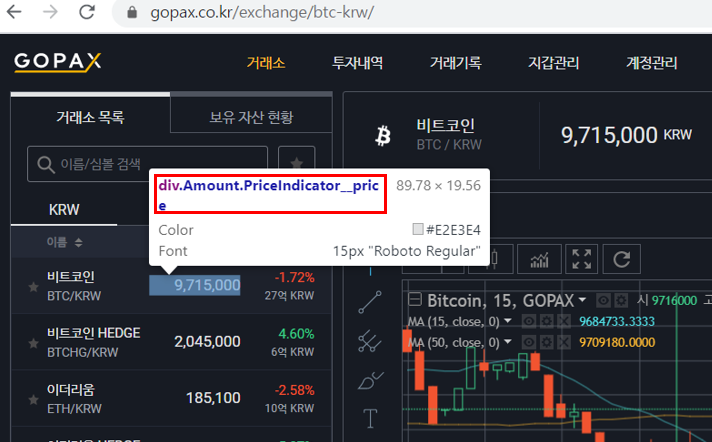
그럼 아래와 같이 코드를 작성하면 원하는 데이터를 얻을 수 있다.
#-*-coding:utf-8-*-
import os
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
# 고팍스 거래소 페이지 URL
URL='https://www.gopax.co.kr/exchange/btc-krw'
def crawl(self):
# webdriver 객체 생성
driver = webdriver.Chrome(ChromeDriverManager().install())
driver.maximize_window()
driver.implicitly_wait(10)
# URL 접근
driver.get(URL)
# 비트코인 현재가 Element에 접근 (div class name을 사용)
bitcoin_price=driver.find_element_by_class_name("PriceIndicator__price")
print(bitcoin_price.text)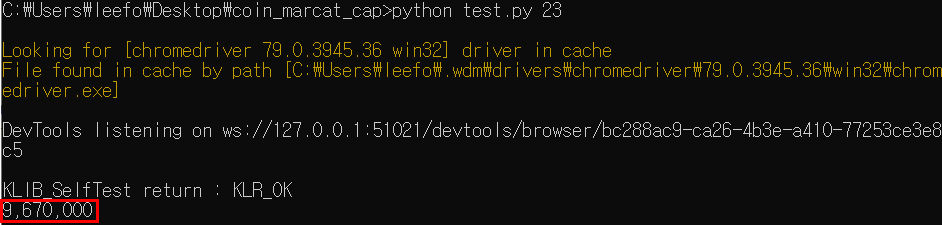
참고로, 위 코드에서는 find_element_by_class_name을 사용하여 원하는 Element에 접근했는데 다음 포스팅에서는, class name 외에도 id, XPath 등 다양한 방법으로 데이터에 접근해보려 한다.
관련포스팅
[파이썬] 동적 웹 크롤링 (3) - Selenium 사용법 (tag, class, xpath 등)
[파이썬] 동적 웹 크롤링 (3) - Selenium 사용법 (tag, class, xpath 등)
아래의 이전 포스팅에서 Selenium 및 브라우저 드라이버 설치, webdriver 객체 생성방법까지 알아보았다. webdriver 객체가 브라우저 제어권을 얻고 타겟 URL에 접근까지 했기 때문에 오늘은 그 후 작업으로 크롤..
liveyourit.tistory.com
[파이썬] 동적 웹 크롤링 (4) - Selenium을 이용한 비트코인 거래소 크롤링
[파이썬] 동적 웹 크롤링 (4) - Selenium을 이용한 비트코인 거래소 크롤링
이전 포스팅에서 알아보았던 Selenium(셀레니움) 사용법을 활용해서 비트코인 거래소 중 하나인 고팍스 메인페이지의 암호화폐 테이블 전체를 크롤링해서 엑셀에 저장해보려 한다. 참고로, webdriver를 설치하고..
liveyourit.tistory.com
'프로그래밍 > 파이썬' 카테고리의 다른 글
| [파이썬] 동적 웹 크롤링 (4) - Selenium을 이용한 비트코인 거래소 크롤링 (5) | 2020.02.01 |
|---|---|
| [파이썬] winreg 모듈을 사용한 레지스트리 등록 (윈도우 자동업데이트 해제) (0) | 2020.01.30 |
| [파이썬] 동적 웹 크롤링 (3) - Selenium 사용법 (tag, class, xpath 등) (6) | 2020.01.26 |
| [파이썬] 동적 웹 크롤링 (1) - Selenium webdriver 설치 및 사용 (0) | 2020.01.23 |
| [파이썬] 파이썬 독학, 진짜 누구나 할 수 있다 :) 초간단 파이썬 설치, IDE 개발 환경, 공부 사이트 추천 (0) | 2020.01.21 |